34 KiB
Docker

Introduction aux conteneurs Docker
Maxime Poullain • Christian Tritten
Un conteneur est un environnement d'exécution
maitrisé et auto-suffisant
qui partage le noyau du système hôte
et qui est isolé du reste du système.
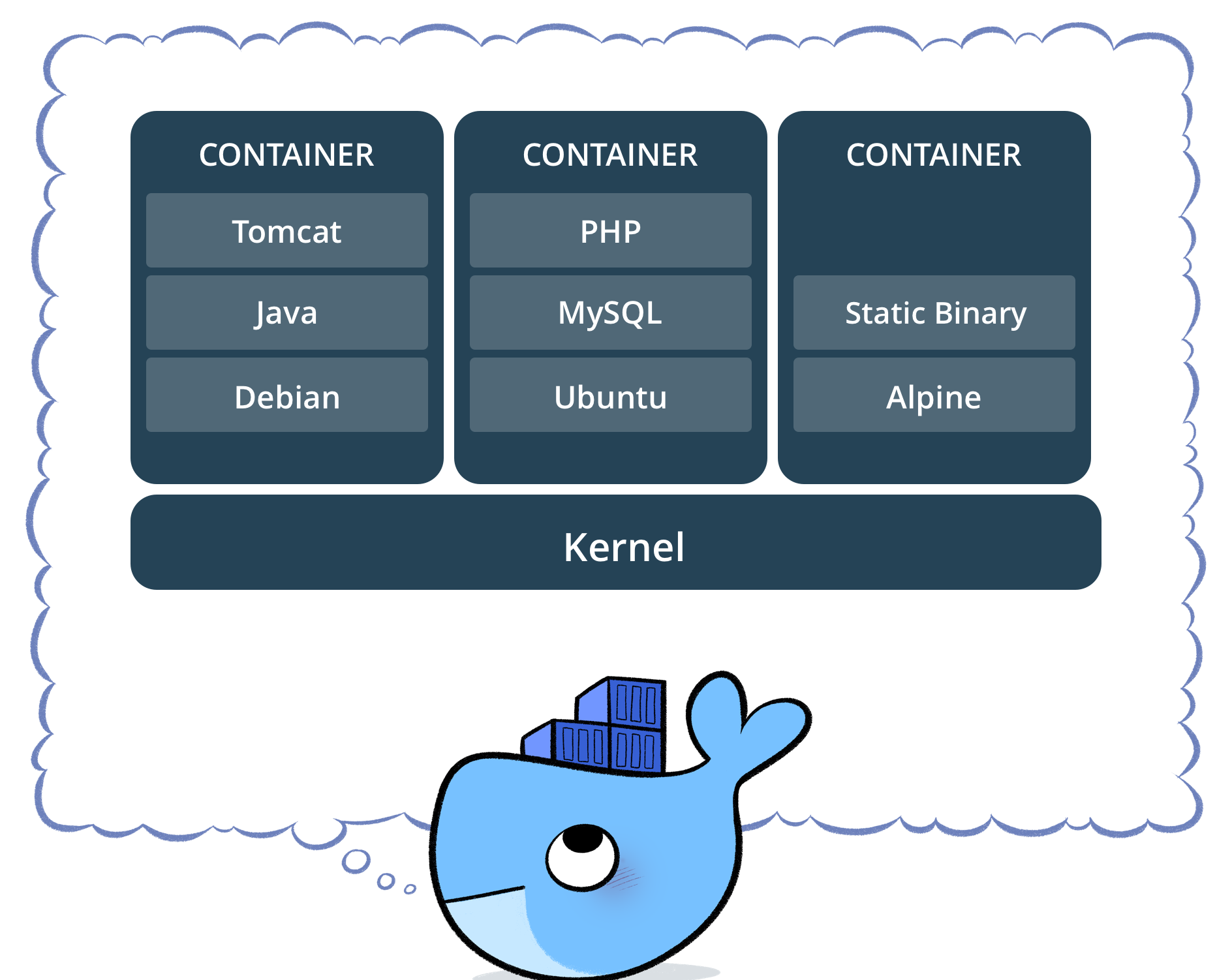
Docker est une technologie
qui permet d'embarquer une application
dans un conteneur virtuel qui pourra
s'exécuter sur n'importe quelle machine.
A quoi ça peut servir ?
-
Cloisonner des applications
(serveur web, de base de donnée, ...) -
Exécuter un traitement ou un calcul ponctuel
(par ex. compilation, tests unitaires, transcodage, etc...) -
Multiplier rapidement le nombre d'instances d'une application
(Orchestration : Docker Swarm, Kubernetes, etc...)
Pour un développeur
-
Utiliser la même pile applicative lors des phases de développement et tests que celle qui tournera en production (et ainsi réduire les sources d'erreurs...)
-
Lancer plusieurs versions distinctes d'une même application sur sa machine
(par ex. plusieurs stacks LAMP différentes)

Principaux objectifs de Docker
-
Faciliter l'empaquetage et la distribution des applications.
-
Simplifier le déploiement et la mise à jour des applications.
-
Épouser les principes des philosophies devops et microservices.
Conteneurisation - Un peu d'histoire
1979
-
Chroot est un utilitaire qui permet de changer la racine du système de fichiers pour un processus et ses enfants.
-
Il s'agit d'une des premières mise en oeuvre d'un concept d'isolation au sein des systèmes d'exploitation.
2000
-
Jails permet d'aller plus loin que chroot en isolant les processus, les utilisateurs, et le réseau sur un système BSD.
-
Chaque jail est un environnement virtuel isolé à l'intérieur duquel on peut déléguer l'administration tout en conservant un bon niveau de sécurité sur le système hôte.
2001
- L'idée est ensuite reprise sur Linux avec Linux VServer qui permet de partitionner le réseau, la mémoire, et le système de fichier.
2002
- La technologie Linux Namespaces qui permet de faire de l'isolation par processus commence à être intégré dans le noyau Linux.
2006
-
Le projet Process Containers est initié chez Google.
-
Il s'agit d'un ensemble de mécanismes permettant de limiter les ressources disponibles pour un processus.
-
Cette technologie, connue sous le nom de Control Groups est intégrée dans le noyaux Linux.
2008
-
LXC (LinuX Containers) propose la première implémentation de conteneurs basée sur les Namespaces et les Control Groups.
-
Reste assez complexe au niveau utilisation.
2013
- Docker voit le jour et est la première solution de conteneurisation vraiment simple à utiliser.
Docker - Un peu d'histoire...
2008

- Solomon Hykes créé la startup dotCloud qui se spécialise comme fournisseur de solutions PaaS (Platform as a Service).
2010 - 2011
-
Solomon Hykes commence à travailler sur le projet de conteneurisation de processus qui deviendra Docker.
-
dotCloud s'installe dans la Silicon Valley.
2013 - 2014
-
Mars 2013, la technologie de conteneur de dotCloud est publié sous licence libre (Apache 2.0).
-
Dès fin 2013 le projet suscite sur Github un énorme engouement de la part des développeurs.
-
Fin 2013 Solomon Hykes décide de créer une nouvelle société entièrement dédiée au projet : Docker Inc.
-
En juin 2014, Docker Inc. publie la version 1.0 de Docker.
2014 - 2016
-
Tous les grands noms du cloud, Amazon Web Services, Microsoft Azure, Google Cloud Platform, OVH, Redhat OpenShift... proposent des offres permettant d'exécuter des conteneurs Docker.
-
Docker devient le standard de facto pour exécuter des conteneurs sous Linux.
-
Les outils d'orchestration de conteneurs Docker commencent à apparaître et à se démocratiser.
-
En 2015, Docker participe à la création de la Cloud Native Computing Foundation aux côtés de Google, IBM, Intel, et bien d'autres...
-
La mission de cette fondation est de populariser les infrastructures reposant sur les conteneurs et la notion de micro-services.
2017
- Fin 2017, Docker annonce le support de Kubernetes dans son offre Entreprise Edition 2.0.
2019
-
Kubernetes a gagné la guerre des orchestrateurs.
Aujourd'hui
-
Les conteneurs sont massivement utilisés partout.
-
La kubecon est un des évènements annuels les plus marquants autour des conteneurs.
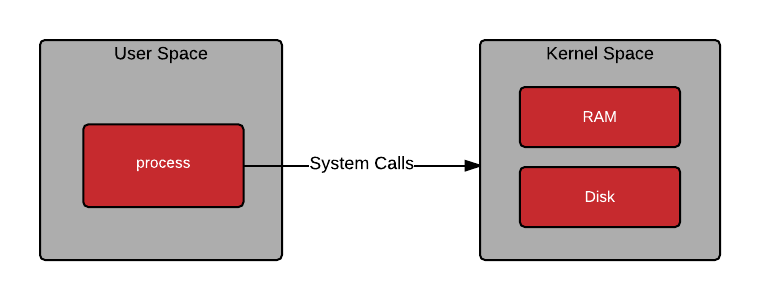
Différences entre un conteneur et une VM ?
-
Une machine virtuelle isole l'intégralité d'un système d'exploitation (kernel + userspace).
-
Un conteneur isole uniquement le userspace et utilise directement le kernel du système hôte.
-
Le kernel (noyau du système d'exploitation) offre la possibilité de virtualiser ses différents sous-systèmes afin de ne présenter au conteneur qu'un sous-ensemble des ressources réellement disponibles.
-
On parle de virtualisation légère.
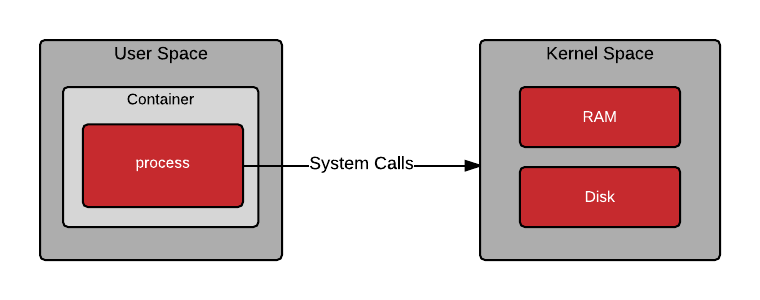
De la VM au Conteneur
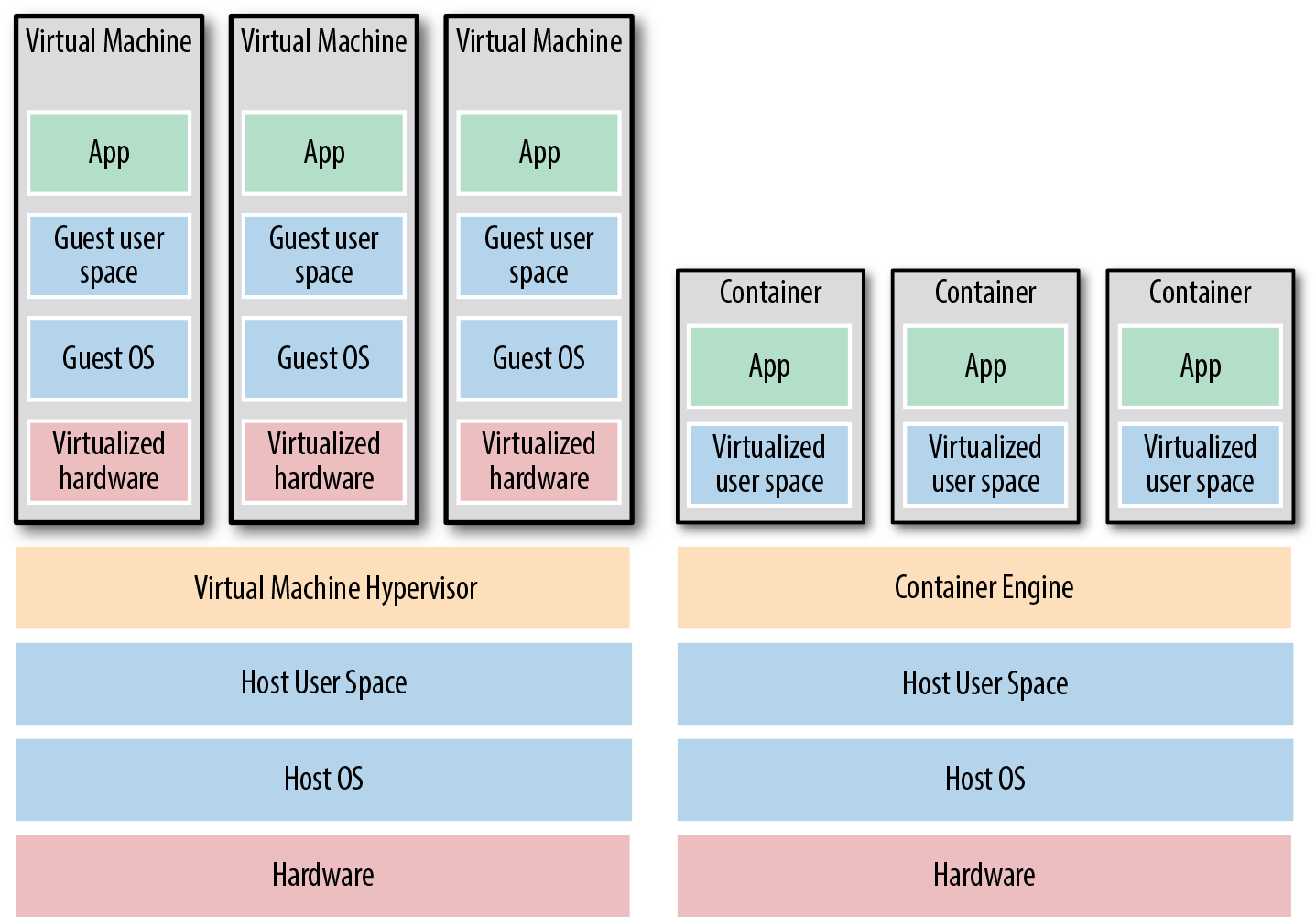
Changement du niveau d'abstraction
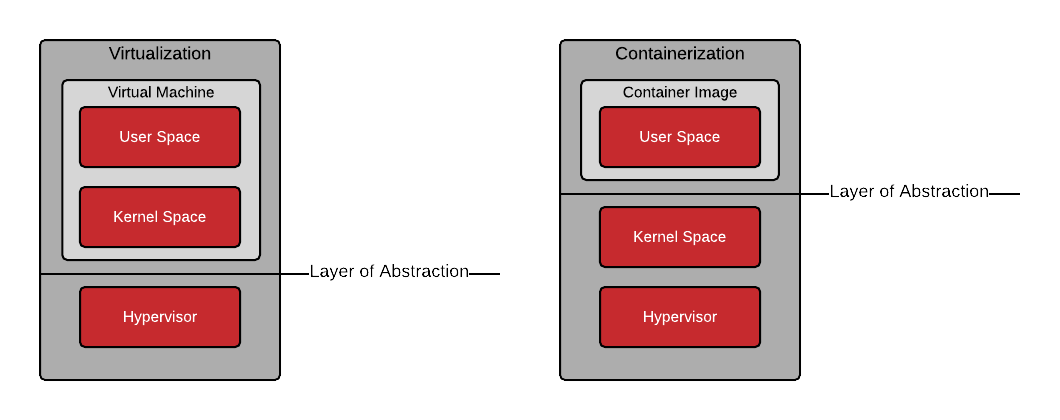
Communication processus <==> noyau
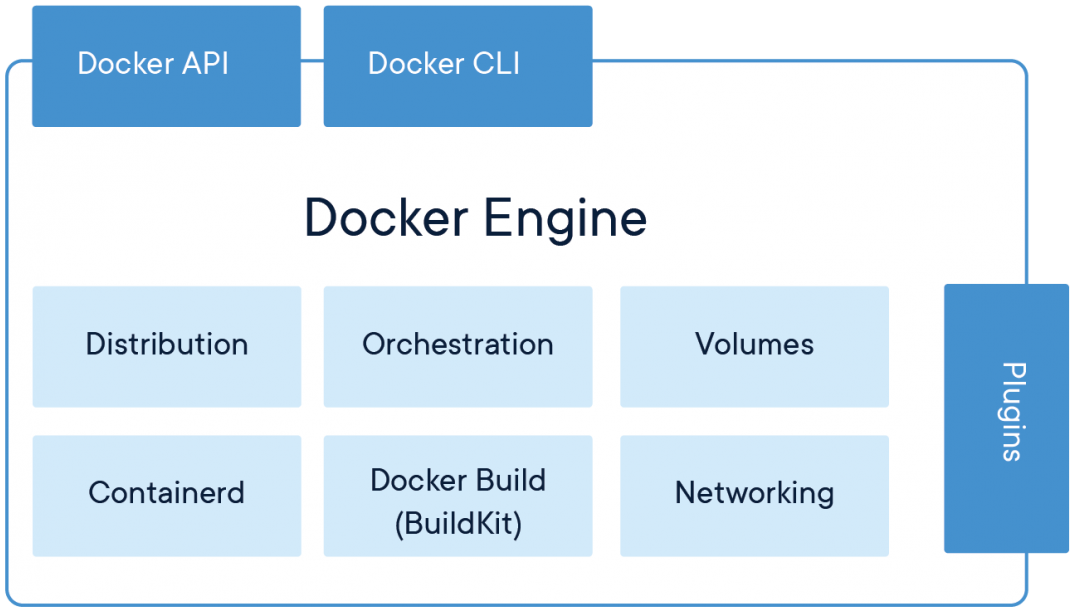
L'outillage Docker
Le Docker Engine
containerd
-
C'est le moteur d'exécution de conteneurs développé par Docker.
-
Il respecte la spécification CRI.
-
Il tourne en tant que daemon sur le système hôte.
-
Il fournit les fonctionnalités pour récupérer et gérer en local les images Docker, gérer le réseau et le stockage.
-
Il pilote l'outil runc pour les opérations de bas niveau qui concernent la création des conteneurs.
containerd
-
Le projet a été offert par Docker à la CNCF en mars 2017.
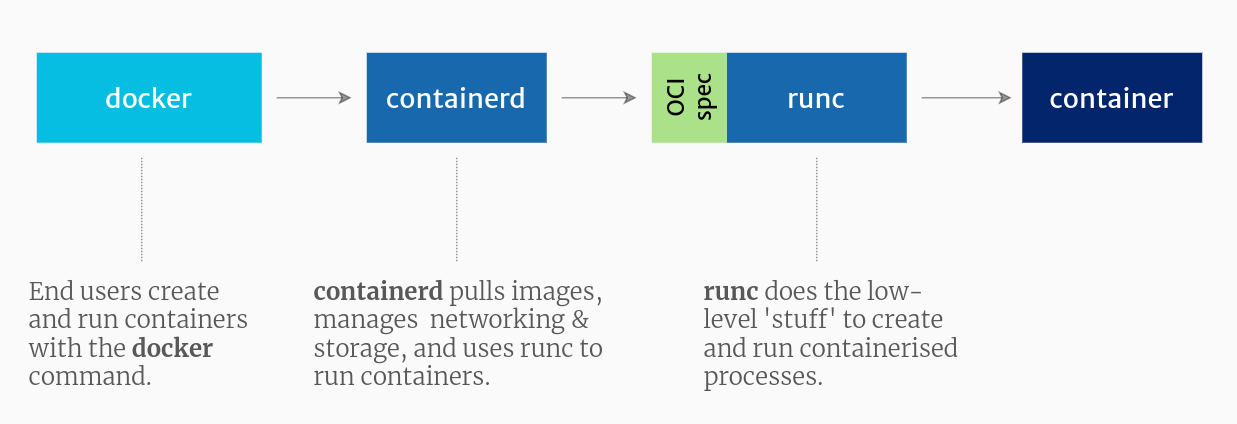
Source : https://www.tutorialworks.com/difference-docker-containerd-runc-crio-oci/
Les images Docker
-
Docker fourni des outils permettant d'empaqueter d'une application sous la forme d'une image légère, portable et auto-suffisante.
-
Ces outils facilitent la création, la mise à jour, le stockage et le transport des images.
-
Docker permet la création de nouvelles images de conteneurs spécialisées à partir d'images de conteneurs plus généralistes.
Le terme Docker
est un raccourci utilisé un peu à tort et à travers pour nommer :
-
la société Docker
-
le Docker Engine
-
la CLI Docker (la commande
docker) -
une image Docker (respectant la spec OCI)
-
un conteneur Docker en cours d'exécution
Quelques avantages des conteneurs Docker
Image en lecture seule
Un conteneur est instancié à partir d'une image en lecture seule. Dans le conteneur en exécution :
-
Pas de mises à jour.
-
Pas de correctifs.
-
Pas de modifications de configuration.
-
Pour mettre à jour le code de l'application ou appliquer un correctif, il faudra créer une nouvelle image et déployer un nouveau conteneur.
L'immuabilité de l'image permet des déploiements sûrs et reproductibles.
-
Pile applicative identique sur le poste du développeur et sur l'environnement de production.
-
Un conteneur aura le même comportement où qu'il soit déployé.
-
Moins de mauvaises surprises lors des passages en production.
Démarrage rapide
-
Démarrer un conteneur est à peine un peu plus coûteux que de lancer un nouveau processus sur le système hôte.
-
En effet un conteneur Docker ne fait tourner que les processus nécessaires à l'exécution d'une application.
(pas d'Init, pas de crontab, pas de...) -
De plus grâce à la technique du Copy-on-Write qui utilise des pointeurs aucune duplication de données n'est nécessaire au lancement du conteneur.
Empreinte stockage faible
-
Les images sont peu volumineuses (comparativement à une VM) et idéalement limitées au seul code applicatif et librairies nécessaires.
-
Les images sont composées de couches superposées qui permettent la gestion des deltas de façon différentielle (FS de type Union).
-
Des conteneurs partageant les mêmes couches d'une image n'ont pas besoin de les dupliquer (technique du Copy-on-Write).
Déployable partout
-
Sur n'importe quel système Linux de même architecture, du cloud à la machine locale.
-
Pas de problème d'incompatibilité de formats d'images (OCI) comme avec les VMs.
Hybrid et Multi-Cloud ready
-
Une fois conteneurisées, les applications sont déployables sur n'importe quelle infrastructure :
-
machines virtuelles,
-
bare metal,
-
cloud public et privés quelque soit la technologie d'hyperviseur sous-jacente.
-
Microservices
- Docker facilite la mise en place d'applications orientées microservices.
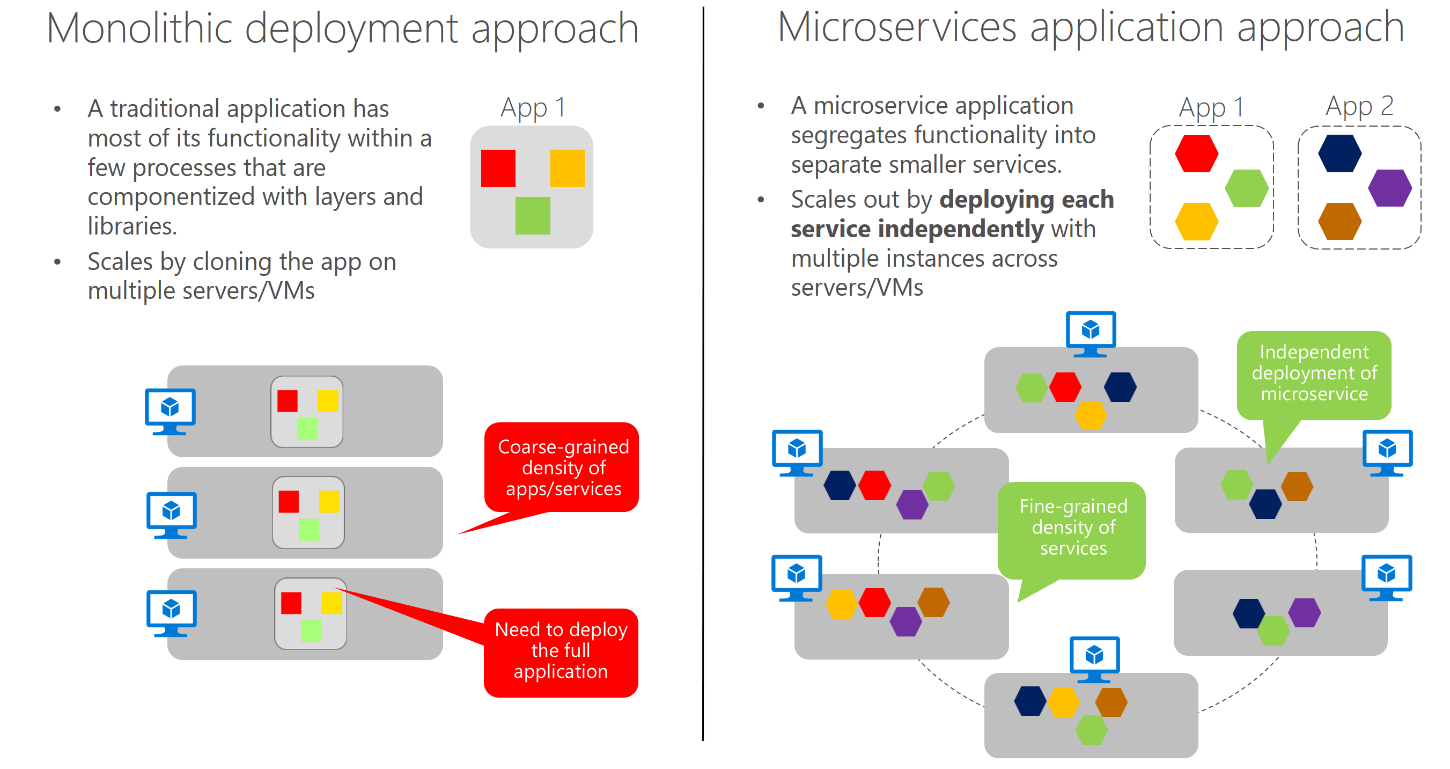
{kind=link}
-
Chacun des composants de l'application (base de données, serveur web, api, ...) peut être :
-
exécuté dans son propre conteneur,
-
mis à jour séparément des autres,
-
mis à l'échelle séparément des autres.
-
Agilité
-
Les conteneurs permettent un fonctionnement plus agile que les VMs
-
Construction automatique,
-
Déploiement rapide,
-
Immutabilité,
-
Patching simplifié,
-
Exécutables via scripts.
-
Quelques inconvénients des conteneurs Docker
Kernel specific
-
La technologie Docker reposent sur des mécanismes spécifiques au noyau de l'OS.
-
Les conteneurs applicatifs Linux ne peuvent donc être exécutés que sur des systèmes Linux.
-
Les conteneurs applicatifs Windows ne peuvent donc être exécutés que sur des systèmes Windows.
-
Architecture specific
- Les conteneurs ne peuvent être exécutés que sur des systèmes hôtes de même architecture processeur (x86, amd64, arm).
Sécurité
-
L'isolation avec des conteneurs est moins forte qu'entre un hyperviseur et ses systèmes invités.
-
Les risques sont essentiellement liés au partage du kernel entre l'hôte et les conteneurs.
-
En cas de compromission du kernel, le système entier et tous ses conteneurs doivent être considérés comme compromis.
Difficultés à conteneuriser
-
Docker permet d'exécuter pratiquement n'importe quelle application dans un conteneur.
-
Mais de part leur conception ou leur choix techniques certaines applications peuvent être délicates à conteneuriser.
Scalabilité complexe
-
Les conteneurs peuvent être faciles à gérer et utiliser sur une station de travail ou quelques serveurs...
-
... mais la scalabilité nécessaire à un environnement de production est un tout autre challenge.
-
Bon c'était vrai en 2015 !
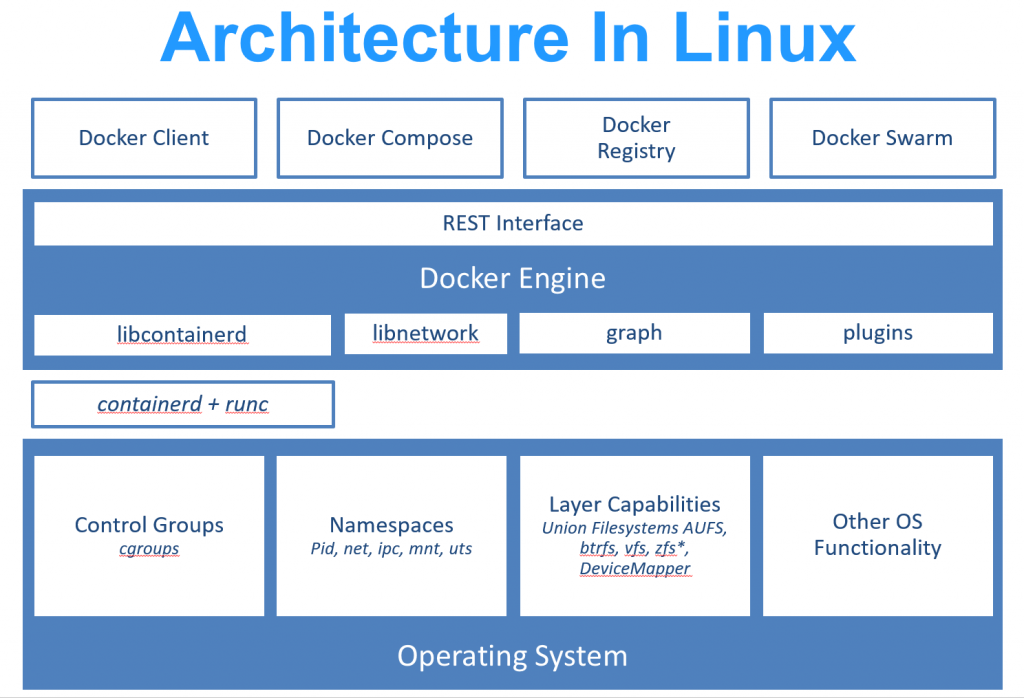
Docker sous Linux
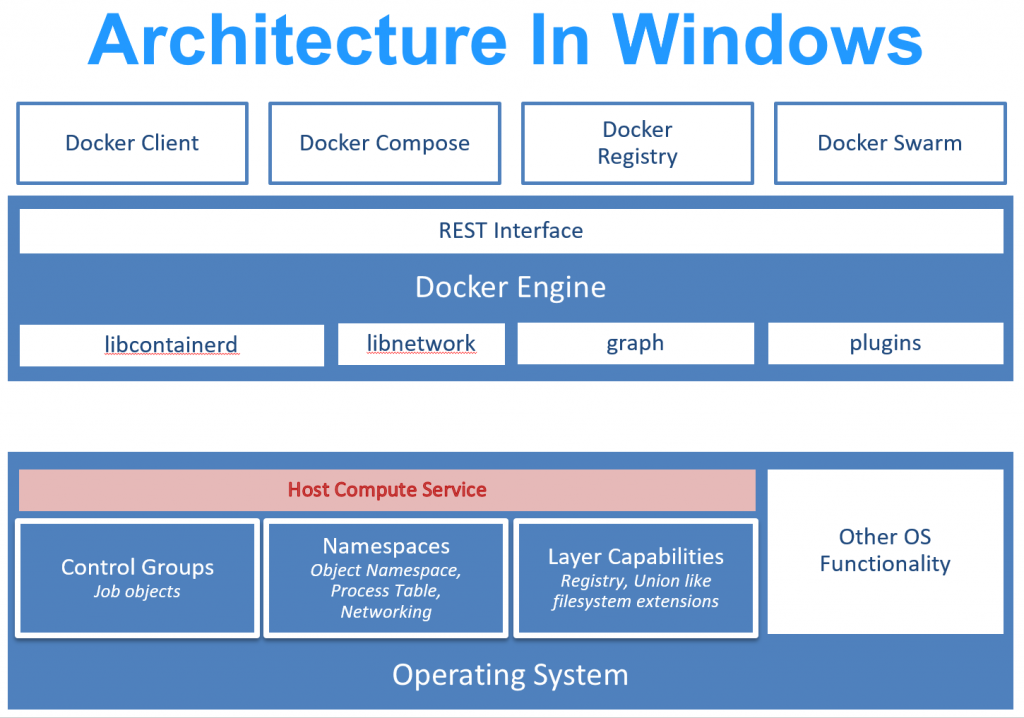
Docker sous Windows
-
A l'origine l'outil boot2docker permettait d'utiliser un hôte Linux minimaliste dans une VM VirtualBox sous Windows.
-
Le Docker Runtime basé sur la technologie Windows Containers est proposé à partir de Windows Server 2016 et autorise pour la première fois la conteneurisation d'applications Windows natives.
-
Pour faire tourner les applications Linux sur un hôte Windows, une couche de virtualisation reste néanmoins nécessaire.
-
Les versions légères core et nano de Windows 2016 Server peuvent être utilisées à l'intérieur des conteneurs mais aussi comme hôte Docker.
-
core est un Windows 2016 Server sans interface graphique.
-
nano est un Windows 2016 Server réduit au minimum sans interface graphique ni shell intéractif.
-
There is no container!
Le conteneur est une notion qui n'existe pas
dans le noyau Linux.
La conteneurisation est rendue possible
par un assemblage de plusieurs technologies
inclues dans le Kernel :
- namespaces
- control groups (cgroups)
- secure computing mode (seccomp)
- capabilities
- linux security modules (lsm)
- ulimit
Ressources systèmes
Ces technologies permettent à chaque conteneur de disposer de ses propres ressources systèmes
- système de fichiers,
- interfaçage réseau,
- liste de processus en cours d'exécution,
- nom d'hôte,
- CPU,
- mémoire,
- etc.
namespaces
Service fourni par le noyau Linux
pour gérer l'isolation des processus :
- mount
- pid
- net
- uts
- ipc
- user
- uts (host and domain names)
Chaque processus ou groupe de processus est placé dans un namespace.
Les namespaces contrôlent ce qu'un processus peut voir.
$ lsns
NS TYPE NPROCS PID USER COMMAND
4026531835 cgroup 82 1931 bob /lib/systemd/systemd --user
4026531836 pid 83 1931 bob /lib/systemd/systemd --user
4026531837 user 75 1931 bob /lib/systemd/systemd --user
4026531838 uts 82 1931 bob /lib/systemd/systemd --user
4026531839 ipc 74 1931 bob /lib/systemd/systemd --user
4026531840 mnt 82 1931 bob /lib/systemd/systemd --user
4026532009 net 74 1931 bob /lib/systemd/systemd --user
4026532436 user 1 10955 bob /home/bob/bin/firefox/firefox-bin -content...
4026532437 ipc 1 10955 bob /home/bob/bin/firefox/firefox-bin -contentproc...
4026532439 net 1 10955 bob /home/bob/bin/firefox/firefox-bin -contentproc...
...
Les namespaces fonctionnent par :
-
filtrage des appels systèmes pour masquer des éléments
- par exemple
psà l'intérieur d'un conteneur n'affichera que les processus du conteneur
- par exemple
-
translation pour convertir des éléments
- par exemple
psà l'intérieur d'un conteneur affichera des PID différents des PID réels
- par exemple
Le Mount namespace (Linux 2.4.19 - 2002)
-
Isolation des points de montage du système de fichiers vus par un groupe de processus.
-
Les points de montage ne sont plus globaux mais spécifiques au namespace.
-
Racine propre (chroot).
Le PID namespace (Linux 2.6.24)
-
Isolation des identifiants de processus (PID).
-
PID 1 init-like par namespace.
-
Chaque namespace possède sa propre numérotation PID.
-
Un processus d'un namespace donné ne peut envoyer de systemcall sur un processus d'un autre PID namespace.
-
Gestion de pseudo-filesystem (ex : /proc) vu par le PID namespace qui le monte.
Un processus possède donc plusieurs PID : un dans le namespace, un en dehors (processus vu par l'hôte).
Les processus http vus depuis le conteneur :
root@bf7fdbc297bb:~# ps auxfww
USER PID %CPU %MEM VSZ RSS STAT START TIME COMMAND
root 1 0.0 0.2 77160 4440 Ss+ 11:55 0:00 httpd -DFOREGROUND
daemon 7 0.0 0.1 366340 3568 Sl+ 11:55 0:02 \_ httpd -DFOREGROUND
daemon 8 0.0 0.1 366340 3568 Sl+ 11:55 0:02 \_ httpd -DFOREGROUND
Les processus http vus depuis l'hôte :
me@docker-node:~$ ps auxfww
USER PID %CPU %MEM VSZ RSS STAT START TIME COMMAND
root 1976 0.0 0.2 77160 4440 Ss+ 11:55 0:00 httpd -DFOREGROUND
daemon 1984 0.0 0.1 366340 3568 Sl+ 11:55 0:02 \_ httpd -DFOREGROUND
daemon 1985 0.0 0.1 366340 3568 Sl+ 11:55 0:02 \_ httpd -DFOREGROUND
Il s'agit bien des mêmes processus.
Le Net namespace (Linux 2.6.19-2.6.24)
-
Isolation du réseau.
-
Chaque namespace possède ses propres interfaces, ports, table de routage...
-
Chaque namespace possède son propre répertoire /proc/net.
### control groups
Service fourni par le noyau pour mesurer et limiter les ressources allouées à un groupe de processus.
$ ls /sys/fs/cgroup
blkio cgmanager cpu cpuacct cpuset devices freezer memory perf_event
$ls /sys/fs/cgroup/cpuset/mon-cgroup
cgroup.procs cpuset.memory_pressure_enabled notify_on_release
cpuset.cpu_exclusive cpuset.memory_spread_page release_agent
cpuset.cpus cpuset.memory_spread_slab tasks
cpuset.mem_exclusive cpuset.mems
cpuset.mem_hardwall cpuset.sched_load_balance
$ cat /sys/fs/cgroup/cpuset/mon-cgroup/cpuset.cpus
0-3
control groups == cgroups
Les control groups régulent ce qu'un processus peut utiliser.
#### Les cgroups et les conteneurs Docker
$ systemd-cgls /docker
Control group /docker:
├─ce1aa87edbef6072f56507874cc122642c66d2360741df4a6c1804204574241e
│ └─3900 /bin/sh
├─0fe89d4808503f2882480e74df69a45cbb50fe8d523d9e586a48176b0f61f60b
│ └─5980 /bin/sh
└─dde507e27656f9349574138160aaac0f3a46a99d2d1f0922013e0604c4abbc5f
├─10195 httpd -DFOREGROUND
├─10231 httpd -DFOREGROUND
├─10232 httpd -DFOREGROUND
└─10233 httpd -DFOREGROUND
secure computing mode (seccomp)
-
Service fourni par le noyau pour filtrer les appels systèmes utilisables par un processus.
-
Il permet d'attacher à un processus une liste blanche d'appels systèmes utilisables, afin d'éviter que ce processus puisse effectuer des opérations jugées dangereuses.
-
Docker propose par défaut un profil seccomp peu restrictif, mais que l'on peut durcir si besoin.
capabilities
-
Service fourni par le noyau pour regrouper des ensembles d'appels systèmes par thématiques.
-
Par défaut Docker désactive certaines 'capabilités'.
Linux Security Modules (LSM)
-
Fonctionnalité du noyau Linux permettant de prendre en charge différents modèles de sécurité.
-
Les modèles les plus connus sont SELinux et AppArmor.
-
Ces modèles appliquent des restrictions en fonction du contexte.
-
Docker fourni des profils pour SELinux et AppArmor.
ulimit
-
Fonctionnalité du noyau Linux permettant de limiter le nombre de processus utilisable.
-
Par défaut Docker limite le nombre processus fils dans un conteneur à 512.
-
Ceci permet d'éviter les fork bomb !
Docker Desktop
-
Sur le poste de travail Docker Desktop propose un environnement Docker près à l'emploi.
-
Pour Mac et Windows (>2010 Professional ou Enterprise 64-bit).
Standardisation
-
Container Runtime Interface (CRI)
spécification d'une API commune à tous les moteurs d'exécution de conteneurs. -
Open Container Initiative (OCI)
spécifications pour les images et conteneurs.
Moteurs de Conteneurs compatibles CRI
-
containerd (initié par Docker en 2016)
-
cri-o (initié par RedHat en 2017)
-
Firecracker (initié par AWS en 2017)
-
Kata Containers (initié par OpenStack en 2017, basé la fusion de Intel Clear Containers et Hyper.sh RunV)
-
gVisor (initié par Google en 2018)
Alternative à Docker : Podman
-
Gestion de conteneurs via une CLI compatible Docker.
-
Poussé par RedHat (en standard sur RHEL 8 / Centos 8).
-
Apporte la fonctionnalité de Pods locaux (notion de base de Kubernetes).
-
Podman n'utilise pas de daemon (contrairement à Docker).
-
Podman s'appuie sur systemd pour la surveillance des conteneurs.
-
Podman utilise les user namespaces pour permettre l'exécution de conteneurs par des utilisateurs non privilégiés.
https://k-7.ch/podman-un-moteur-de-conteneur-deamon-less.html
Opérations de base sur les conteneurs
Docker CLI
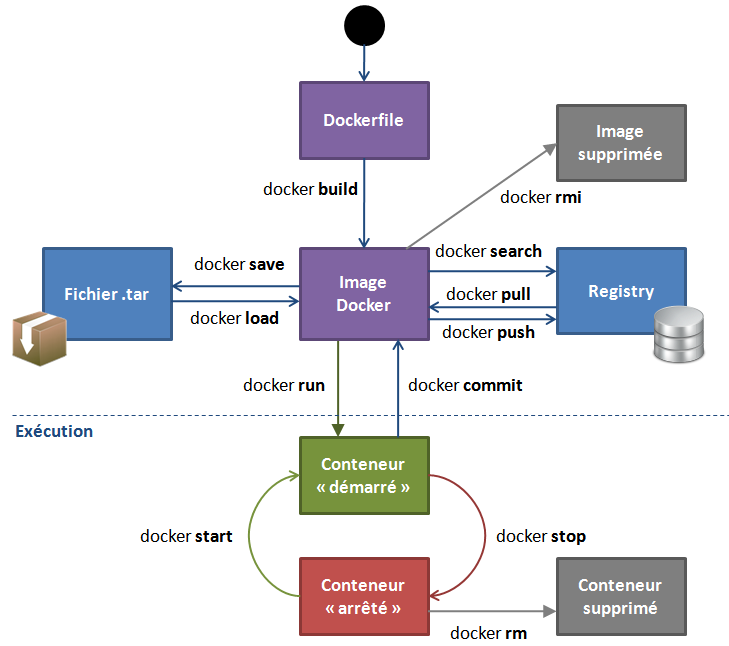
Docker run
Permet d'instancier un conteneur à partir d'une image.
docker run [OPTIONS] IMAGE [COMMAND] [ARG...]
Option | Description
-
| -
--detach, -d | Mode détaché : lance le conteneur à l'arrière plan
--name NAME | Donne un nom au conteneur
--interactive, -i | Connexion à l'entrée standard du conteneur
--tty, -t | Nous souhaitons ouvrir un pseudo-terminal
Exemple :
docker run --name test debian /bin/cat /etc/resolv.conf
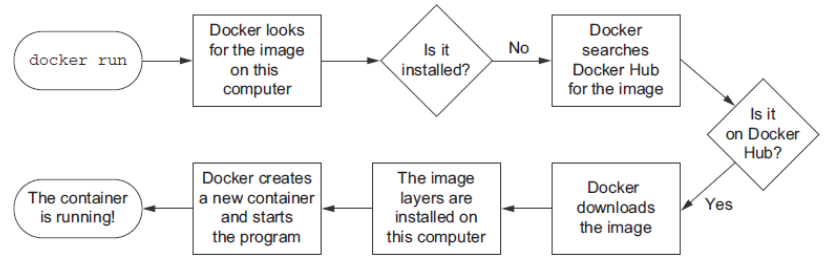
Lancer un conteneur en mode intéractif
$ docker run -ti busybox
/ # ps -ef
PID USER TIME COMMAND
1 root 0:00 sh
7 root 0:00 ps -ef
/ # ls
bin dev etc home proc root sys tmp usr var
/ # exit
-
En combinant les options
-tet-ion ouvre une session à l'intérieur du conteneur. -
Lorsqu'on quitte le shell, le conteneur est automatiquement arrêté (mais pas détruit).
Lancer une commande dans un conteneur et récupérer son résultat
$ docker run busybox /bin/cat /etc/passwd
root:x:0:0:root:/root:/bin/sh
daemon:x:1:1:daemon:/usr/sbin:/bin/false
bin:x:2:2:bin:/bin:/bin/false
sys:x:3:3:sys:/dev:/bin/false
sync:x:4:100:sync:/bin:/bin/sync
mail:x:8:8:mail:/var/spool/mail:/bin/false
www-data:x:33:33:www-data:/var/www:/bin/false
operator:x:37:37:Operator:/var:/bin/false
nobody:x:99:99:nobody:/home:/bin/false
- Ici le conteneur retourne le résultat de la commande sur la sortie standard, rend de suite la main, puis est automatiquement arrêté (mais pas détruit).
### Lancer un conteneur à l'arrière plan
$ docker run -d httpd
dde507e27656f9349574138160aaac0f3a46a99d2d1f0922013e0604c4abbc5f
-
Docker retourne l'identifiant du conteneur créé et rend de suite la main.
-
Le conteneur continue à tourner à l'arrière plan jusqu'à ce que le processus plante ou qu'on l'arrête explicitement.
Lister les conteneurs
docker ps [OPTIONS]
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
dde507e27656 httpd "httpd..." 2 seconds ago Up 2 seconds 80/tcp reverent...
0fe89d480850 busybox "/bin/sh" 44 minutes ago Up 42 minutes vigilant...
ce1aa87edbef busybox "/bin/sh" About an ho... Up About a... trusting...
-
Par défaut seuls les conteneurs actuellement en cours d'exécution sont affichés.
-
L'option
-apermet d'afficher tous les conteneurs quelque soit leur état.
Stopper des conteneurs
| Commande | Description |
|---|---|
exit |
Ou n'importe quelle autre commande permettant de terminer le processus principal depuis le conteneur |
docker stop CONTAINER |
Le processus principal à l'intérieur du conteneur reçoit un SIGTERM, et après un délai de grâce de 10s un SIGKILL |
docker kill CONTAINER |
Le processus principal à l'intérieur du conteneur reçoit un SIGKILL ou tout autre signal spécifié avec l'option -shttps://medium.com/@gchudnov/trapping-signals-in-docker-containers-7a57fdda7d86 |
docker stop $(docker ps -a -q) |
Stoppe tous les conteneurs |
Autres opérations
| Commande | Description |
|---|---|
docker start CONTAINER [CONTAINER...] |
Démarre un ou plusieurs conteneurs stoppés |
docker restart CONTAINER [CONTAINER...] |
Redémarre un ou plusieurs conteneurs |
docker rm CONTAINER [CONTAINER...] |
Supprime un ou plusieurs conteneurs |
docker container prune |
Supprime tous les conteneurs |
docker pause CONTAINER |
Suspend le conteneur |
Docker logs
Afficher les logs d'un conteneur.
docker logs -f mon_conteneur
Option | Description
-
| -
--details | Affiche des détails supplémentaires
--follow, -f | Continue à afficher les logs de manière intéractive
--since | Affiche les logs à partir d'une certaine date
--tail | Affiche les n dernières lignes
--timestamps, -t | Affiche les timestamps
Par défaut, docker logs affiche la sortie d'une commande jouée à l'intérieur du conteneur exactement comme elle apparaîtrait si on la jouait interactivement dans un terminal.
Les commandes Linux ouvrent généralement 3 flux I/O :
STDIN, STDOUT, and STDERR.
Flux | Description
-
| -
STDIN | Flux d'entrée de la commande (ex: clavier, sortie d'une autre commande...)
STDOUT| Flux de sortie pour les messages 'normaux' de la commande
STDERR| Flux de sortie pour les messages d'erreur de la commande
Par défaut docker logs affiche les flux STDOUT et STDERR de la commande jouée à l'intérieur du conteneur.
Logging drivers
Driver | Description
-
| -
none | Aucune gestion de logs pour le conteneur.
json-file | Les logs sont formatés en JSON. C'est le choix par défaut.
syslog | Ecrit les logs dans syslog (Le démon syslog doit tourner sur la machine hôte).
journald | Ecrit les logs dans journald (Le démon journald doit tourner sur la machine hôte).
gelf | Ecrit les logs au format Graylog Extended Log Format, en vue d'un traitement par Graylog ou Logstash.
... | Y'en a d'autres !
Actuellement, seuls les drivers json-file et journald sont exploitables via la commande docker logs.
Logging - bonnes pratiques
Docker derrière un proxy
Configuration du Docker-Engine
Pour forcer le docker-engine à utiliser un proxy :
/etc/systemd/system/
docker.service.d/http-proxy.conf
[Service]
Environment="HTTP_PROXY=http://proxy.example.com:3128/"
Environment="HTTPS_PROXY=http://proxy.example.com:3128/"
systemctl daemon-reload
systemctl restart docker.service
Travaux pratiques

Docker Network
Comment fonctionne le réseau avec Docker ?
Lister les réseaux existants
docker network ls
$ docker network ls
NETWORK ID NAME DRIVER SCOPE
b69de2fd946f bridge bridge local
90d83d01c5cd formation bridge local
e59c9b6ccc29 host host local
e15666fbca66 none null local
(+ le driver container !)
Réseau none
-
Un conteneur démarré sur le réseau
noneutilisant le drivernullsera complètement isolé. -
Seule l'interface loopback sera disponible dans le conteneur.
-
Idéal pour des conteneurs de calculs qui n'ont besoin d'aucun accès à des ressources externes.
$ docker run --net=none -ti busybox
/ # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1
inet 127.0.0.1/8 scope host lo
Réseau host
-
Un conteneur démarré sur le réseau
hostse trouvera dans le même namespace réseau que l'hôte lui-même. -
Le conteneur pourra donc utiliser directement la stack réseau de l'hôte.
-
Performances natives. (pas de NAT, de bridge ni de veth)
$ docker run --net=host -ti busybox
/ # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1
inet 127.0.0.1/8 scope host lo
2: enp10s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc...
inet 10.6.208.11/24 brd 10.6.208.255 scope global dynamic...
3: ...
Réseau host
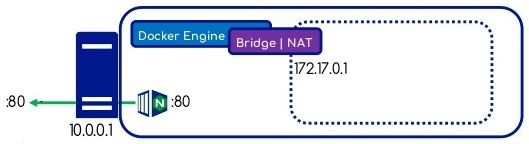
Attention aux conflits dans l'utilisation des ports réseaux.
Réseau container
-
Un conteneur démarré en utilisant le driver
containerse trouvera dans le même namespace réseau que l'autre conteneur spécifié. -
Les deux conteneurs partageront les mêmes interfaces réseaux, réseaux, règles iptables, etc...
-
Il pourront communiquer entre eux en utilisant l'interface loopback.
Réseau container
docker run -ti --name c1 busybox
/ # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1
inet 127.0.0.1/8 scope host lo
1077: eth0@if1078: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu...
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
$ docker run -ti --name c2 --net container:c1 busybox
/ # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
1077: eth0@if1078: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu...
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
Ici les conteneurs c1 et c2 partagent les mêmes interfaces réseau (lo et eth0).
Réseau Bridge
-
Par défaut les conteneurs sont démarrés sur le réseau Docker interne
bridgenommédocker0. -
Ces conteneurs n'exposent aucune connectivité au monde externe mais peuvent communiquer entre eux à la condition qu'ils soient placés sur le même hôte.
$ docker run -ti busybox
/ # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1
inet 127.0.0.1/8 scope host lo
13: eth0@if14: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu...
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
Bridge - Schéma
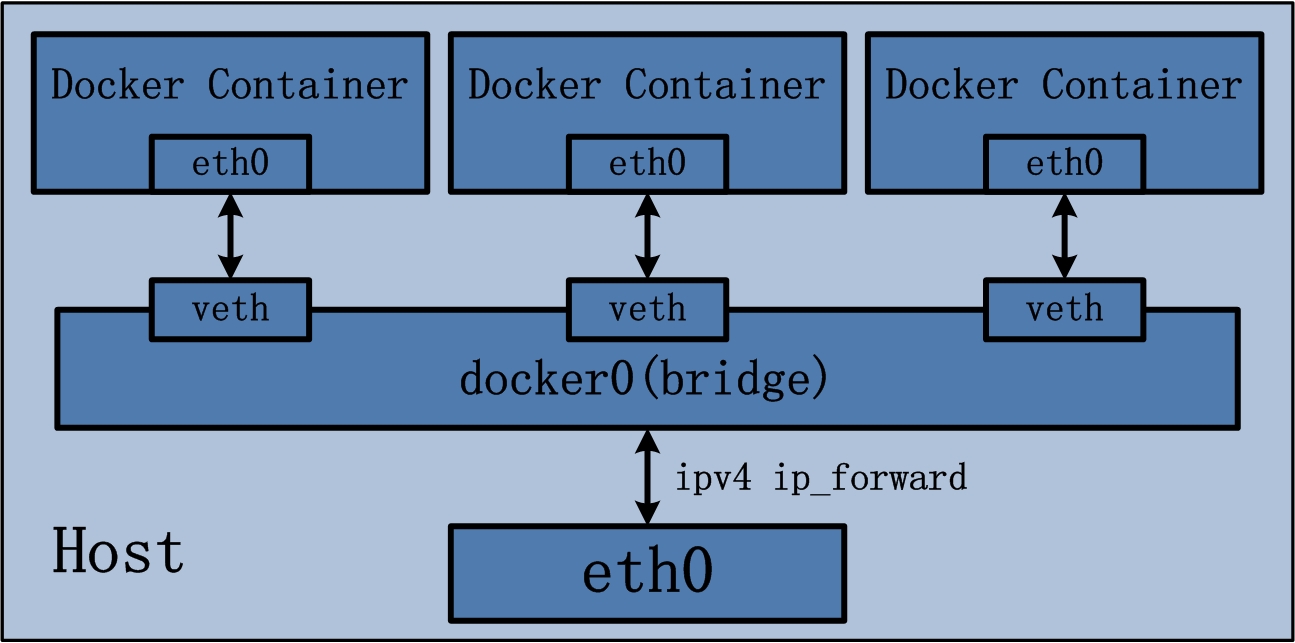
Bridge - Fonctionnement
-
Les adresses sont allouées par défaut sur le subnet interne
172.17.0.0/16(configurable avec--bip). -
Le trafic sortant passe par une règle iptables MASQUERADE.
-
le trafic entrant passe par une règle iptables DNAT.
Bridge - Exposition de ports
-
Pour exposer un port au niveau du conteneur, on peut ajouter l'option
--exposequi permet de surcharger la directiveEXPOSEd'un Dockerfile. -
Ceci permet d'attaquer le service à partir de l'adresse IP du conteneur.
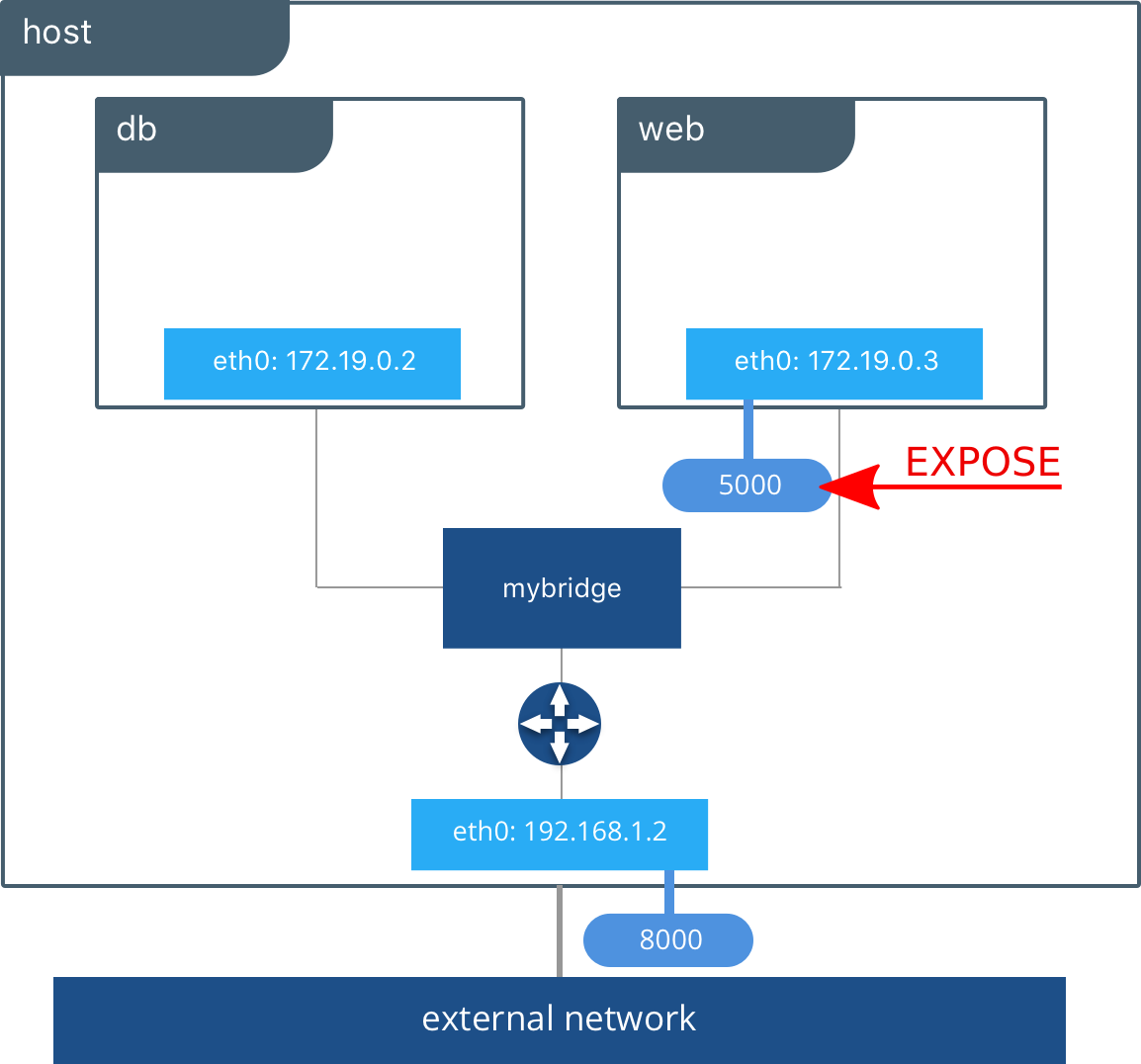
Bridge - Mapping de ports
-
Pour publier un port au niveau de l'hôte on peut ajouter l'option
--publishqui permet de mapper un port déjà exposé sur le conteneur vers l'hôte. -
On le formate de la manière :
--publish HOST-PORT:CONTAINER-PORT -
Avec
--publish-allon ouvre tout les ports exposés d'un conteneur (ce n'est pas forcément conseillé).
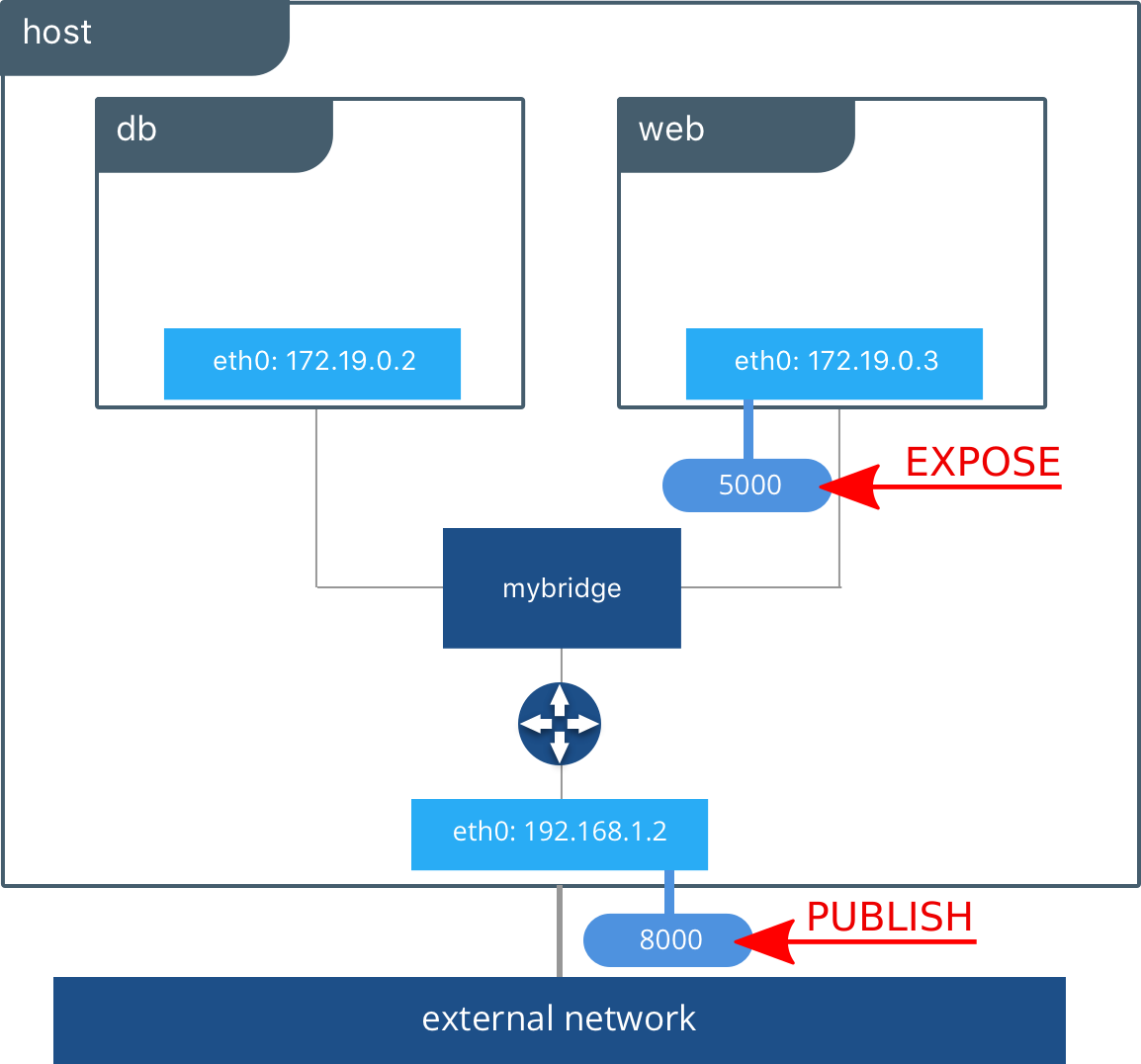
Exemple
$ docker run -d --name web --publish 8000:5000 httpd:2.4
On ouvre le port 8000 de l'hôte et on le mappe au port 5000 de notre conteneur.
Commande network
-
Créer un réseau bridge
$ docker network create --driver bridge NETWORK -
Afficher les détails d'un réseau
$ docker network inspect NETWORK -
Supprimer un réseau existant
$ docker network rm NETWORK -
Attacher un réseau existant à un conteneur existant
$ docker network connect NETWORK CONTAINER
Docker DNS embarqué
-
Sur le réseau bridge par défaut, il n'est pas possible de résoudre les adresses IP des conteneurs depuis leurs noms.
-
Il faut pour ça créer un réseau personalisé.
-
Ainsi, tous les conteneurs démarrés sur ce réseau vont pouvoir communiquer entre eux grâce à leurs noms.
-
Le fichier /etc/resolv.conf du conteneur est automatiquement alimenté avec nameserver 127.0.0.11.
Exemple
- Ajout d'un nouveau réseau de type Bridge :
$ docker network create --driver bridge mon-reseau
- Démarrage d'un conteneur sur le nouveau réseau avec l'option
--network:
$ docker run --detach --name apache --publish 8080:80 \
--network mon-reseau httpd:2.4
Si on ajoute d'autres conteneurs sur ce réseau, il pourront communiquer entre eux directement en utilisant le nom attribué avec l'option --name.
Plus de détails sur les réseaux Docker
Travaux pratiques