22 KiB
Docker

Swarm
Maxime Poullain • Christian Tritten
Le passage à l'échelle d'une infrastructure Docker
nécessite des outils adaptés.
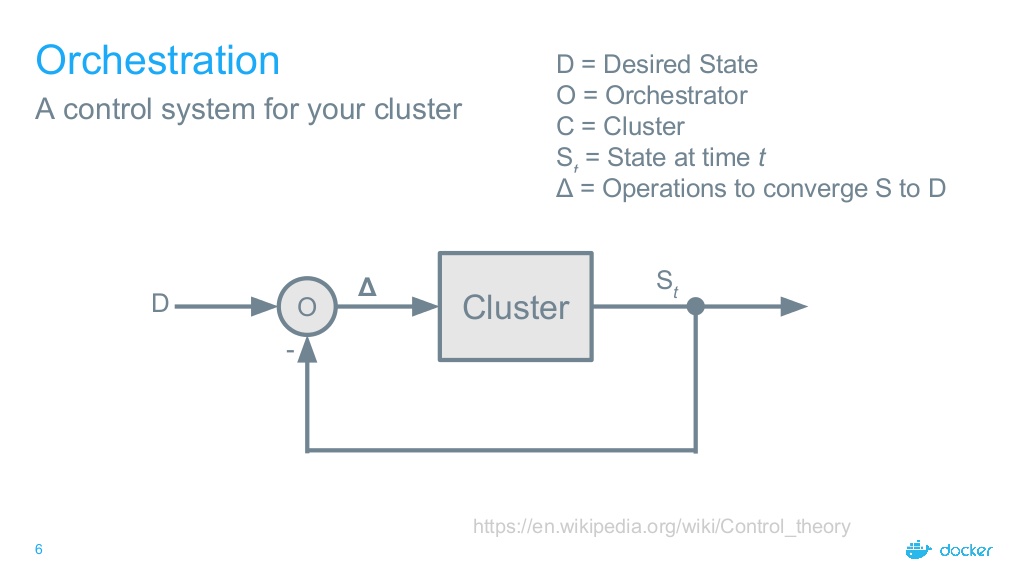
Orchestrateur de conteneurs
Un orchestrateur de conteneurs permet
de construire (facilement) un système distribué.
Fonctionnalités d'un orchestrateur (1/2)
-
Gestion d'un ensemble de machines (cluster)
Extension horizontale de la capacité du système par l'ajout de nouvelles machines -
Gestion des déploiements de conteneurs (scheduler)
Selon des critères : label, affinité, charge, ... -
Gestion de la résilience
Via des tests de santé périodique sur les conteneurs et les hôtes
Fonctionnalités d'un orchestrateur (2/2)
-
Gestion d'un réseau distribué
Qui s'étend sur l'ensemble des machines du cluster -
Gestion de la haute disponibilité des applications
En créant plusieurs instances d'une même application sur des hôtes différents -
Gestion de la découverte de services
Pour détecter automatiquement les nouvelles instances d'une application
Principe d'un orchestrateur
Les principaux orchestrateurs
-
Swarm (Docker)
-
Kubernetes (Google)
-
OpenShift (RedHat)
-
Mesos/Marathon (Apache)
-
Nomad (HashiCorp)
-
Rancher
-
...
Docker Swarm

- Orchestrateur maison de Docker Inc.
- Très bien intégré dans Docker (rien à installer)
- Facile à prendre en main
- Solution idéale pour les petits environnements
Swarm - Fonctionnalités
-
Gestion du cluster
-
Ajout/retrait de machines
-
Maintient opérationnel de l'état du cluster
-
Chiffrement des transactions entre les noeuds (control plane)
-
-
Orchestration des déploiements
-
Placement des conteneurs
-
Stratégies / Filtres
-
-
Gestion d'applications multi-conteneurs (Stack)
-
Réseau distribué (Overlay)
-
Mise à l'échelle
-
Équilibrage de charge
-
Gestion de la résilience
Concepts
La terminologie Swarm
-
node
-
task
-
service
-
stack
-
network
-
secret / config
Node
-
Un noeud (node) est une instance de Docker Engine intégrée dans le cluster Docker Swarm.
-
On peut joindre autant de noeuds que nécessaire au cluster.
-
On peut également retirer des noeuds si besoin.
Deux types de noeuds :
-
Manager
- Maintient l'état du cluster
- Orchestre les tâches (tasks) sur les noeuds actifs
-
Worker
- Reçoit les tâches (tasks) envoyées par les noeuds manager
- Exécute les tâches localement
-
Par défaut les noeuds de type manager sont aussi des worker.
-
Il est possible de configurer un noeud manager pour qu'il fasse seulement office de manager (
drain). -
Un noeud peut changer de rôle au cours de son existence en passant de worker à manager ou inversement (
promote/demote).
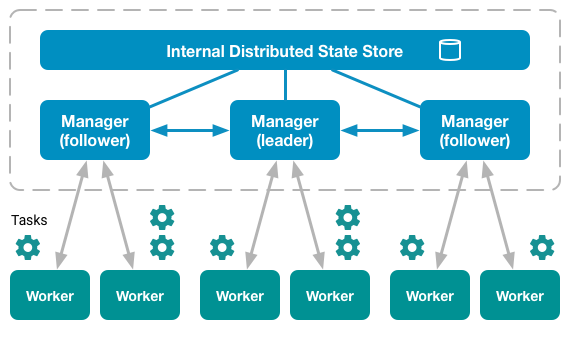
Un noeud Manager peut être dans l'un des états suivants :
-
Leader : noeud manager primaire du système, il prend les décisions d'orchestration au sein du cluster.
-
Reachable : noeud pouvant devenir leader en cas de défaillance de l'actuel noeud leader.
-
Unavailable : noeud non joignable d'un point de vue réseau.
-
Afin d'augmenter la résilience du cluster, il est recommandé d'opter pour un nombre impair de noeuds de type manager :
-
Avec 3 noeuds managers, le système peut survivre à une perte maximum d'1 manager.
-
Avec 5 noeuds managers, le système peut survivre à une perte maximum de 2 managers.
-
L'augmentation du nombre de noeuds manager ne procure pas de meilleures performances au système global.
| Managers | Majorité Quorum | Tolérence de perte |
|---|---|---|
| 1 | 1 | 0 |
| 2 | 2 | 0 |
| 3 | 2 | 1 |
| 4 | 3 | 1 |
| 5 | 3 | 2 |
| 6 | 4 | 2 |
| 7 | 4 | 3 |
| 8 | 5 | 3 |
| 9 | 5 | 4 |
Niveaux de disponibilité d'un noeud :
-
Active
-
Pause
-
Drain
Niveau Active :
-
Le noeud peut recevoir de nouvelles tâches de la part de l'orchestrateur.
-
C'est le niveau de fonctionnement normal.
Niveau Pause :
-
Le noeud ne peut plus recevoir de nouvelles tâches de la part de l'orchestrateur.
-
Les éventuelles tâches en cours d'exécution sur ce noeud continuent d'être exécutées sur ce noeud.
Niveau Drain :
-
Le noeud ne peut plus recevoir de nouvelles tâches de la part de l'orchestrateur.
-
Les éventuelles tâches en cours d'exécution sur ce noeud sont automatiquement basculées sur un noeud actif.
-
Ce mode est prévu pour la maintenance de l'hôte.
Task
-
Une tâche (task) est l'unité atomique directement orchestrable au sein du cluster Swarm.
-
Une tâche correspond à l'exécution d'un conteneur sur un noeud du cluster.
-
Les noeuds de type manager assignent les tâches directement aux noeuds de niveau active selon le mode de mise à l'échelle défini pour le service (replicated/global).
-
Si l'exécution d'une tâche échoue, l'orchestrateur la supprime et en créé une nouvelle en remplacement.
Service
-
Un service est la formalisation de tâches (tasks) qui seront exécutées par les noeuds de niveau active.
-
Un service peut donc avoir plusieurs tâches.
2 modes pour la scalabilité d'un service :
-
Replicated : le manager génère des tâches de type réplica pour le service jusqu'à atteindre le nombre de réplicas souhaité et les distribue sur les noeuds active du cluster.
-
Global : le manager lance une tâche du service sur chaque noeud disponible dans le cluster, ce qui peut se révéler pratique dans le cas d'agents de monitoring par exemple.
La montée de version pour un service donné peut être gérée de façon séquentielle (une tâche remplacée après l'autre) ou parallèle n tâches du service remplacées en même temps).
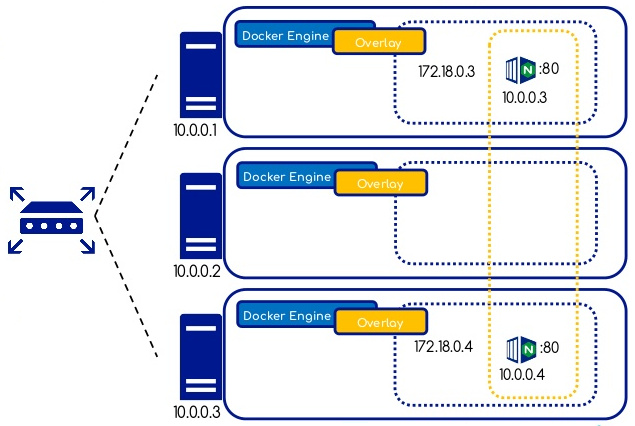
Overlay Network
-
Un réseau de type
overlayest distribué sur l'ensemble des noeuds du cluster swarm. -
Il permet de connecter un ou plusieurs services à l'intérieur du cluster Swarm sans avoir besoin de publier des ports réseau sur les hôtes.
-
La technologie
VXLANest utilisée pour créer les réseaux overlay au dessus du réseau existant. -
Par défaut tout le trafic transitant sur un réseau overlay est en clair (pour des raisons de performance).
-
Il est possible de chiffrer un réseau overlay donné (Kernel
IPSECencryption) via l'ajout d'une option lors de sa création.
Le tunnel ainsi créé permet aux conteneurs
de communiquer même s'ils sont placés
sur des hôtes différents.
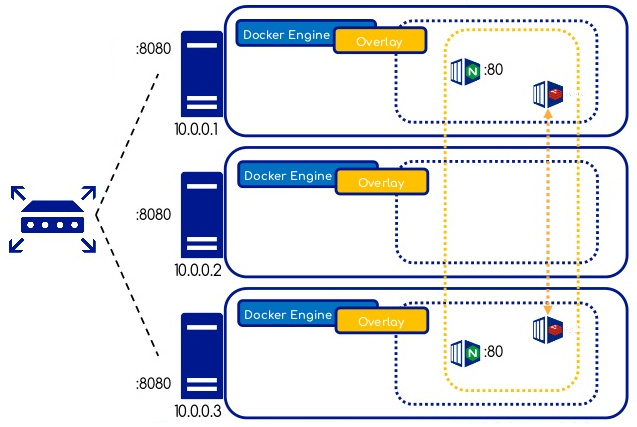
Chaque conteneur démarré sur un réseau overlay se voit attribuer deux adresses IP : une pour la communication entre les conteneurs du réseau (10.0.0.x) et une pour la VXLAN Tunnel End Point address (VTEP) (172.18.0.x).
Swarm permet de publier des services à l'extérieur en assignant un PublishedPort à un service donné.
Un port ainsi publié est ouvert sur tous les noeuds du cluster. Les requêtes sont routées automatiquement.
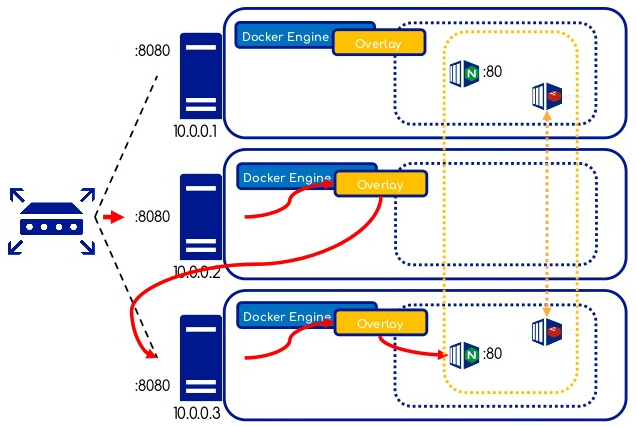
VIP et DNS
-
Par défaut une adresse IP virtuelle (VIP) et une entrée DNS sont créées pour chaque service géré par Swarm, le rendant ainsi disponible par son nom aux conteneurs présents sur le même réseau overlay.
-
Swarm intègre un service de DNS interne permettant de résoudre facilement le nom d'un service.
Load Balancing interne
Swarm utilise un mécanisme interne de répartition de charge pour distribuer les requêtes aux services.
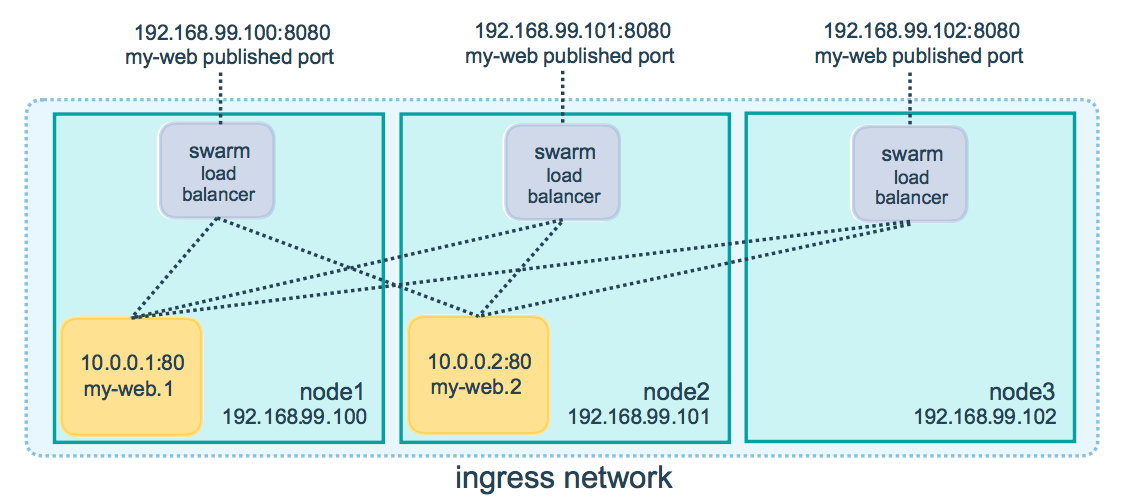
Load Balancing externe
Des composants externes tels des load balancers peuvent être placés en amont du cluster Swarm et accéder à un service sur le port publié (PublishedPort) à partir de n'importe quel noeud du cluster.
Reverse Proxy et Load Balancing HAProxy
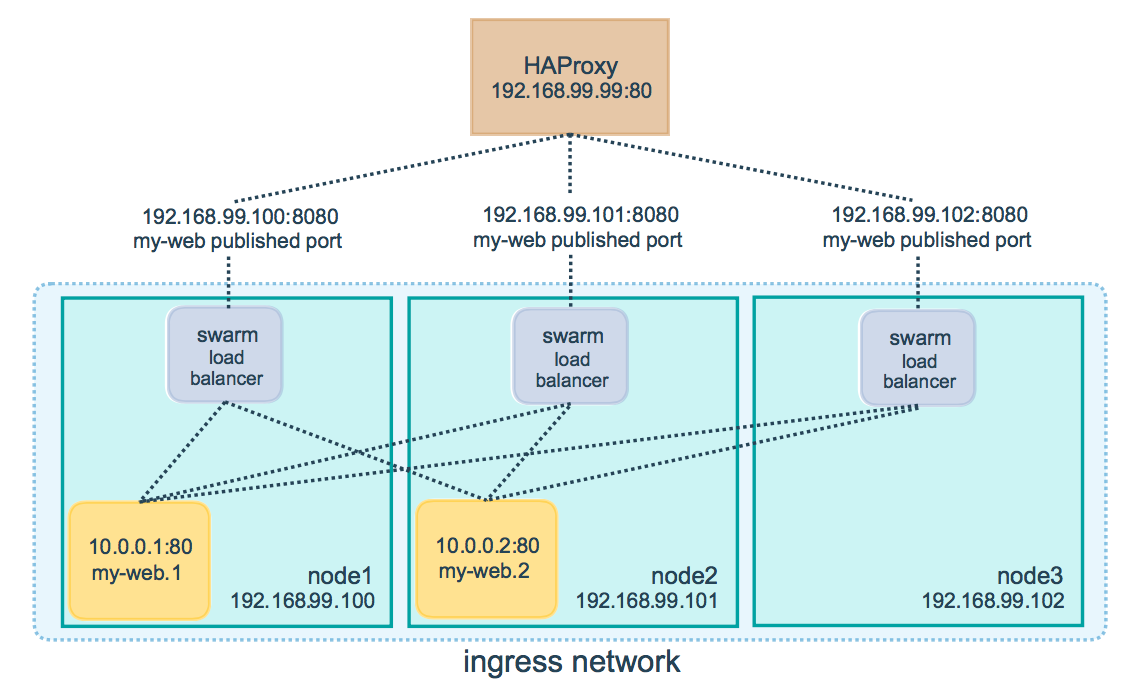
Swarm se charge ensuite de router de façon transparente les requêtes à destination du service sur l'un des noeuds exécutant une tâche correspondant au service demandé.
Stack
-
Une stack est la formalisation d'une application composée d'un ou plusieurs services.
-
Elle se présente sous la forme d'un fichier de description
docker-compose.yml -
Il devient ainsi possible de déployer une application complexe sur l'ensemble du cluster.
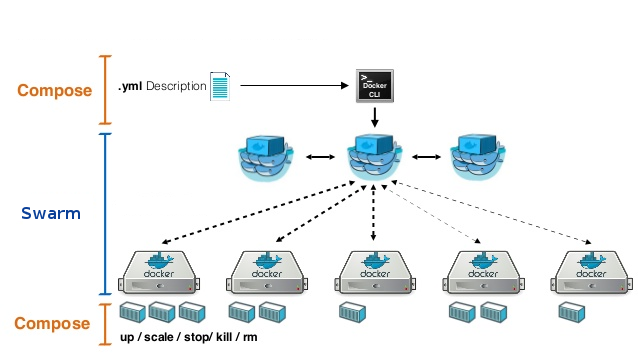
Stack = Swarm + Compose
Secret
Gestion sécurisée des données sensibles.
-
Exemples de données sensibles :
-
Nom d'utilisateur
-
Mot de passe
-
Certificats et clés TLS
-
Clés SSH
-
Nom d'une base de données
-
nom d'un serveur interne
-
Chaines de caractères ou fichier binaire (< 500 Kb)
-
-
Limitation : les secrets sont utilisables seulement avec les services Swarm.
-
Les secrets sont chiffrés et stokés par Swarm.
-
Les secrets sont distribués aux différents noeuds du cluster et transmis seulement aux services qui en font la demande.
-
Les secrets sont présentés aux conteneurs d'un service sous la formation d'un dossier en mémoire RAM monté dans
/run/secrets. Ce dossier contient les secrets déchiffrés. -
A partir de Docker 17.06 il est possible de définir l'emplacement où un secret doit être monté à l'intérieur du conteneur.
Config
-
Le concept de
configest disponible à partir de Docker 17.06. -
Il s'agit de l'équivalent des secrets mais pour des données non sensibles (par exemple un fichier de configuration).
-
Limitation : les configs sont utilisables seulement avec les services Swarm.
-
Le but des configs est d'éviter :
- les montages de type
bind-mountpour faire de la configuration, - l'utilisation de variables d'environnement.
- les montages de type
-
Les données des configs ne sont pas chiffrées et sont montées directement dans système de fichiers du conteneur (sans utilisation de RAM disks).
Manipuler Swarm
Les fondamentaux
Initialisation du cluster
Sur l'hôte Docker qui sera le premier manager du cluster
$ docker swarm init --advertise-addr MANAGER-IP
Swarm initialized: current node (dxn1zf6l61qsb1josjja83ngz) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join \
--token SWMTKN-1-2scvxnrfa53pxfcf7w1qvdm25ofv6lg776tszvnjbtg727ozau \
192.168.99.100:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow
the instructions.Swarm initialized: current node (dxn1zf6l61qsb1josjja83ngz)
is now a manager.
Pour ajouter un worker ou un manager au cluster une seule commande suffit.
- On peut retrouver cette commande depuis le premier manager :
$ docker swarm join-token worker
To add a worker to this swarm, run the following command:
docker swarm join \
--token SWMTKN-1-2scvxnrfa53pxfcf7w1qvdm25ofv6lg776tszvnjbtg727ozau \
192.168.99.100:2377
$ docker swarm join-token manager
To add a manager to this swarm, run the following command:
docker swarm join \
--token SWMTKN-1-2scvxnrfa53pxfcf7w1qvdm25ofv6lg776tszvnjbtg727ozau \
192.168.99.100:2377
Par exemple, on ajoute un worker en jouant la commande récupérée précédemment.
Sur le futur noeud worker :
$ docker swarm join \
--token SWMTKN-1-2scvxnrfa53pxfcf7w1qvdm25ofv6lg776tszvnjbtg727ozau \
172.16.2.11:2377
This node joined a swarm as a worker.
Pour administrer les noeuds du Swarm on doit exécuter les commandes depuis un manager.
Pour afficher les liste des noeuds :
$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
3raehvrbi5u0rz4y2kaqreakr * docker-node-1 Ready Active Leader
jel9o08m2tcfmpyryt1d3nr59 docker-node-2 Ready Active Reachable
lennvj9r57wgl6cwi5k7ac0cb docker-node-5 Ready Active
om4pm2xcc9fl4uyehzeuwfklm docker-node-3 Ready Active Reachable
ynj6x2tblko0ulvaz6ojrxueu docker-node-4 Ready Active
-
Pour transformer un noeud worker en manager :
$ docker node promote NODE -
Et inversement :
$ docker node demote NODE -
Pour supprimer un noeud du Swarm:
$ docker node rm NODE
Travaux pratiques

TP Initialisation d'un cluster Swarm
Services
Pour lancer un service sur le cluster Swarm :
docker service create
$ docker service create --name busybox busybox sleep 600
docker service create [OPTIONS] IMAGE [COMMAND] [ARG...]
Créer un nouveau service
| Option | Description |
|---|---|
--constraint |
Placement constraints |
--network |
Network attachments |
--name |
Service name |
--publish |
Publish a port as a node port |
--replicas |
Number of tasks |
... |
https://docs.docker.com/engine/reference/ commandline/service_create/ |
- Lister les services du cluster :
$ docker service ls
ID NAME MODE REPLICAS IMAGE
uutgao0sp6qi busybox replicated 1/1 busybox:latest
-
Supprimer un service :
$ docker service rm SERVICE -
Mettre à jour un service avec :
$ docker service update [OPTIONS] SERVICE -
Pour revenir à la version précédente de la configuration d'un service :
$ docker service rollback SERVICE
Par exemple, il est possible d'ajouter une contrainte sur un service pour qu'il ne démarre que sur un noeud spécifique.
$ docker service update --constraint-add 'node.hostname == <NODE.HOSTNAME>' busybox
On peut revenir à la configuration précédente en utilisant la fonctionnalité de rollback.
$ docker service rollback busybox
Attention, on ne peut pas revenir en arrière plusieurs fois d'affilé.
Pour voir en détail les tasks d'un service :
docker service ps SERVICE
$ docker service ps busybox
ID NAME IMAGE NODE DESIRED STATE
uzb1ovvp4tnx busybox.1 busybox:latest docker-node-1 Running
cs5vud4gpq1n \_ busybox.1 busybox:latest docker-node-2 Shutdown
$ docker service ps busybox --filter desired-state=Running
ID NAME IMAGE NODE DESIRED STATE
uzb1ovvp4tnx busybox.1 busybox:latest docker-node-1 Running
Pour mettre à l'échelle un service :
docker service scale SERVICE=REPLICAS
$ docker service scale busybox=3
busybox scaled to 3
$ docker service ps busybox
ID NAME IMAGE NODE DESIRED STATE
uzb1ovvp4tnx busybox.1 busybox:latest docker-node-1 Running
cs5vud4gpq1n \_ busybox.1 busybox:latest docker-node-2 Shutdown
pmdpmocyf106 busybox.2 busybox:latest docker-node-1 Running
hzk9x2ak8win busybox.3 busybox:latest docker-node-1 Running
Pour déployer une stack
docker stack deploy [OPTIONS] STACK
-
Une multitude de nouvelles options a été ajouté dans le version 3 du format docker-compose.yml.
docker stack COMMAND
Gère une stack Docker
Commande | Description
-
| -
deploy | Déploie une nouvelle stack ou met à jour une stack existante
ls | Liste les stacks
services | Liste les services de la stack
ps | Liste les tasks de la stack
rm | Supprime la stack
Travaux pratiques
TP Déploiement d'applications sur Swarm
Dépannage
Se sortir de situations difficiles
Dépannage Manager
Si un noeud Manager est défaillant, la solution peut être de lui faire quitter puis rejoindre le cluster.
-
Rétrograder le Manager en worker :
docker node demote <MANAGER> -
Supprimer le Node du cluster :
docker node rm <NODE>. -
Re-joindre le Node au cluster :
docker swarm join.
Source : https://docs.docker.com/engine/swarm/admin_guide/#troubleshoot-a-manager-node
Sauvegarde de l'état d'un Manager
-
Si l'auto-lock est activé, le désactiver.
-
Stopper Docker sur l'hôte cible.
-
Sauvegarder le répertoire
/var/lib/docker/swarm -
Redémarrer Docker.
Source : https://docs.docker.com/engine/swarm/admin_guide/#back-up-the-swarm
Restaurer l'état d'un Manager
-
Stopper Docker sur l'hôte cible.
-
Supprimer le dossier
/var/lib/docker/swarm -
Restaurer le dossier
/var/lib/docker/swarmdepuis une sauvegarde. -
Démarrer Docker sur le nouveau noeud, et réinitialiser le noeud avec
docker swarm init --force-new-cluster -
Vérifier l'état du swarm.
Source : https://docs.docker.com/engine/swarm/admin_guide/#recover-from-disaster
Logging
Les logs des démons Docker et Swarm se situent :
| Operating system | Location |
|---|---|
| RHEL, Oracle Linux | /var/log/messages |
| Debian | /var/log/daemon.log |
| Ubuntu 16.04+, CentOS | Use the command journalctl -u docker.service |
| Ubuntu 14.10- | /var/log/upstart/docker.log |
| macOS | ~/Library/Containers/com.docker.docker/Data/com.docker.driver.amd64-linux/console-ring |
| Windows | AppData\Local |
Enable Debugging
Pour activer le debugging du démon Docker, éditer le fichier /etc/docker/daemon.json pour y ajouter :
{
"debug": true
}
Rédémarrer le démon ou recharger sa configuration.
Source : https://docs.docker.com/engine/admin/
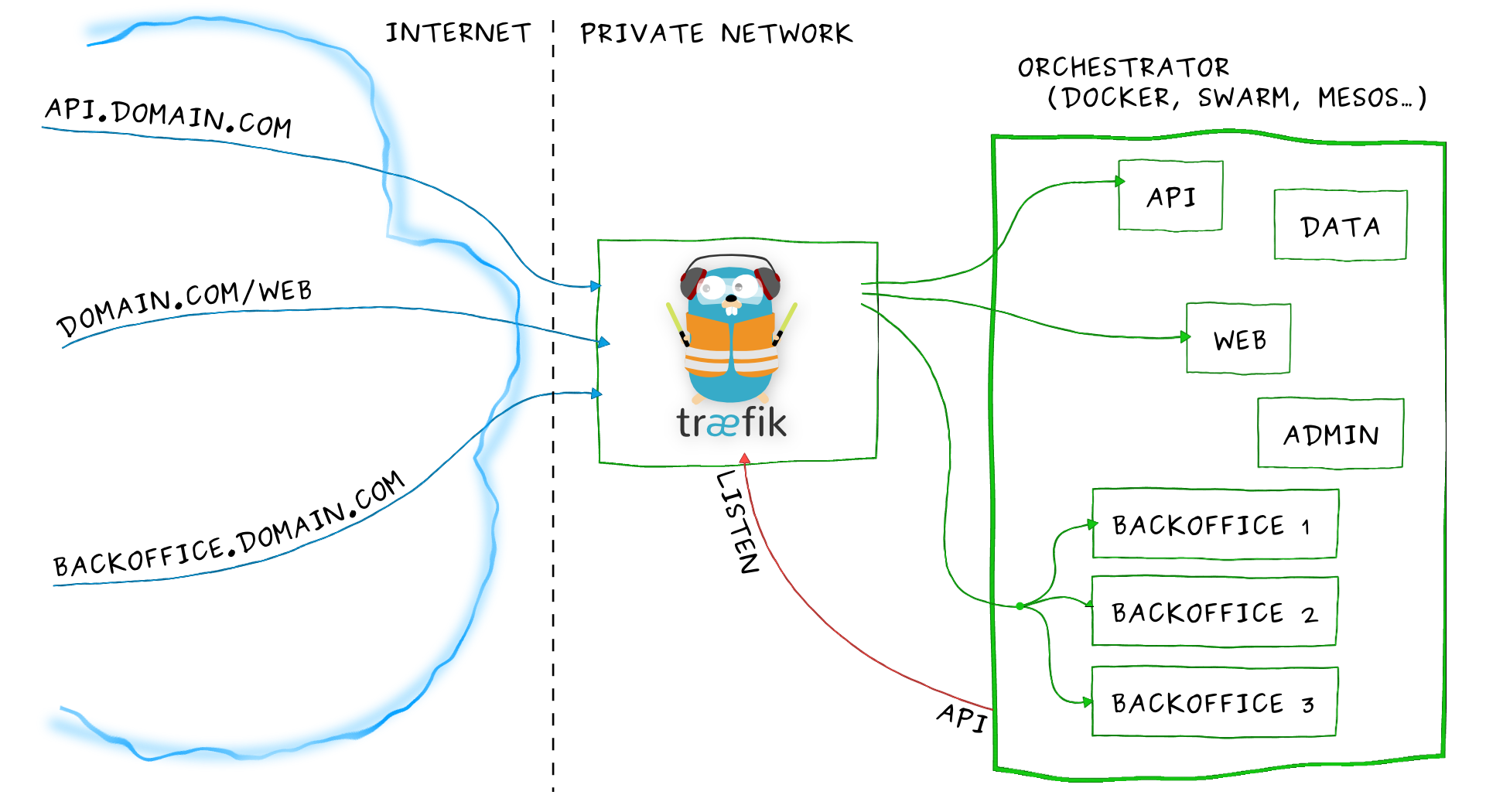
Reverse Proxy
Accéder au cluster Swarm depuis l'extérieur
Traefik
-
Reverse Proxy HTTP & Load Balancer
-
Rapide
-
Supporte une grande variété de backends
(Docker, Swarm, Kubernetes, Mesos/Marathon, Consul, Etcd, Rest API, file...) -
Configuration dynamique pour simplifier l'accès aux applications orientées micro-services
-
Gestion automatique des certificats TLS avec Let's Encrypt
-
Interface web de supervision
Fonctionnement
-
Traefik se lance dans un conteneur sur le cluster et se connecte à la socket Docker pour écouter les évènements du cluster.
-
Les conteneurs applicatifs déclarent des labels traefik.* afin de se signaler auprès de Traefik.
Schéma de principe
Travaux pratiques
Plus de détails sur Traefik v2
- https://blog.containo.us/traefik-2-0-docker-101-fc2893944b9d
- https://blog.containo.us/traefik-2-tls-101-23b4fbee81f1
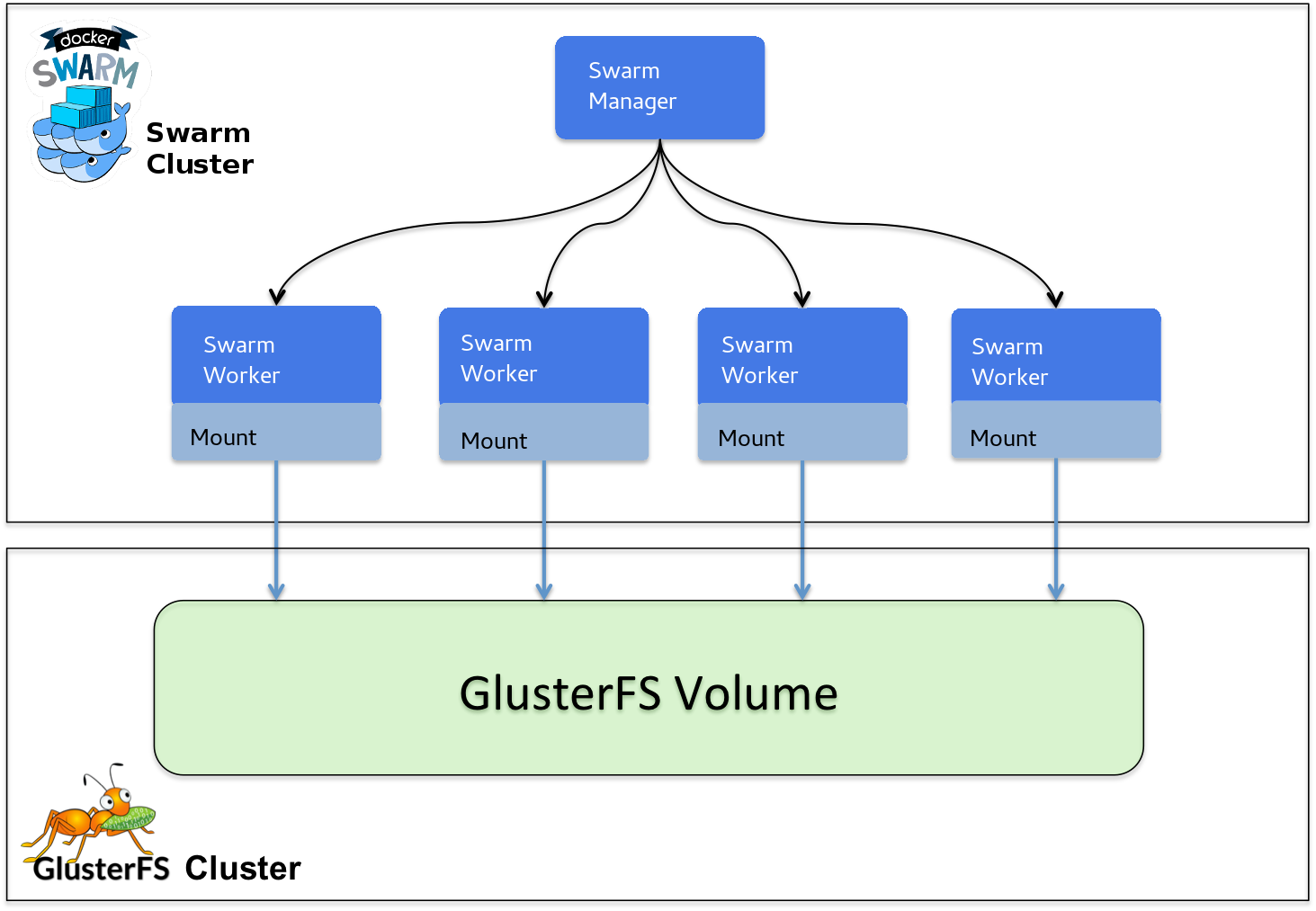
Stockage distribué
GlusterFS
Lorsque des applications sont déployées sur plusieurs noeuds, il devient nécessaire de :
-
Rendre certaines données accessibles sur tous les noeuds du cluster Swarm.
-
Rendre possible la persistance des données des conteneurs sur n'importe quel noeud.
-
GlusterFS est un système de fichiers libre distribué, qui permet de stocker jusqu'à plusieurs pétaoctets.
-
GlusterFS réplique automatiquement les données sur tous les noeuds du cluster de stockage.
GlusterFS repose sur un modèle client-serveur.
-
Les serveurs sont déployés comme des "briques de stockage", chaque serveur exécutant un daemon qui exporte un système de fichier local comme un volume.
-
Les clients sont sans état, et ne communiquent pas entre eux. Ils peuvent monter les volumes exportés par les serveurs.